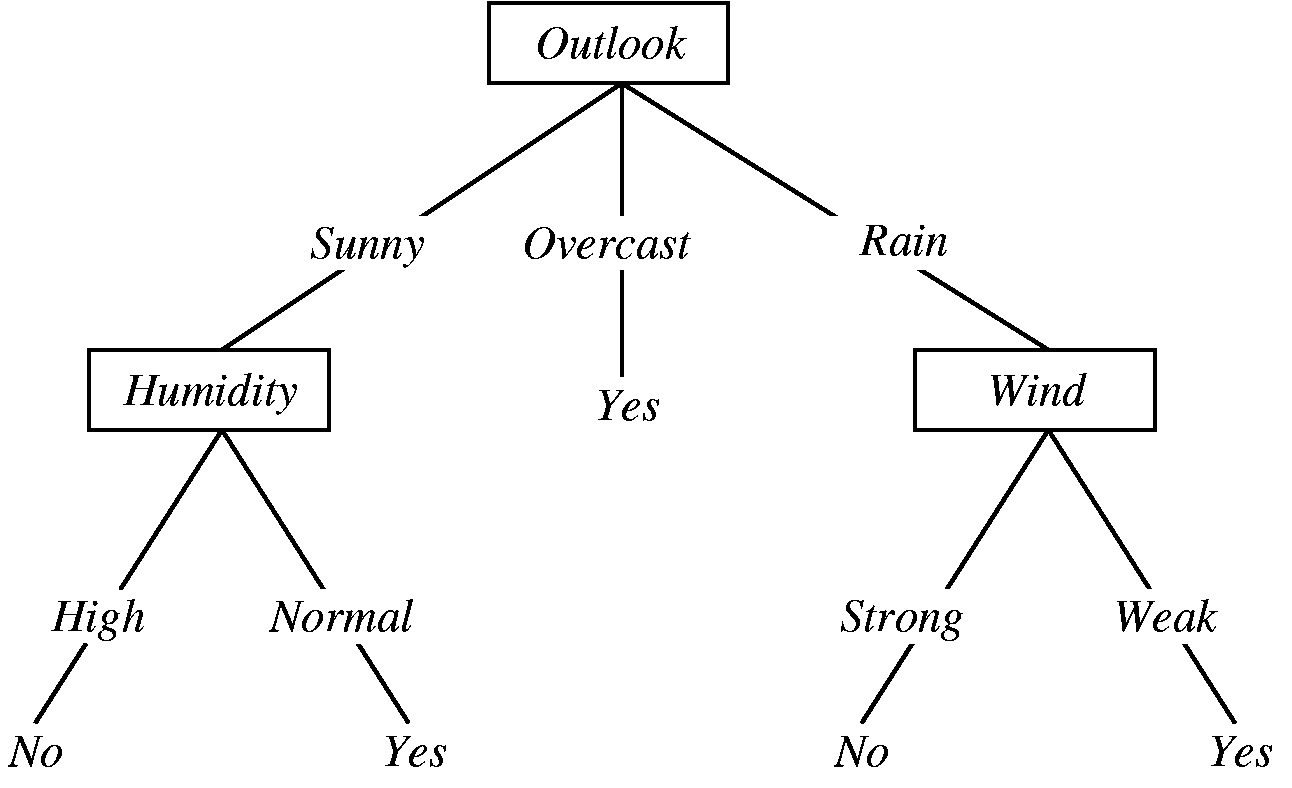
Implementação ID3
Como prometido nesse post iremos analisar a implementação do algoritmo de árvore de decisão ID3, o algoritmo foi implementado em Java 7 e no final do post irei colocar o link para o repositório que contém os códigos fontes.
A seguir iremos fazer uma análise das principais classes que compõe o algoritmo:
Start.java
Classe inicial do projeto, responsável por realizar as chamadas dos métodos de carregamento dos atributos, carregamento da base e geração da árvore, assim como impressão da árvore no arquivo de resultados.
public class Start {
/**
* Função main, ela que irá carregar os dados e iniciar o processamento da árvore.
*
* @param args
*/
public static void main(String[] args) {
//Caminho para a pasta onde será lido o arquivo com a base de dados
String path = "C:\\Users\\davidson.sestaro\\Dropbox\\IA\\";
//Carrega os atributos da base de dados
ListDiscreteAttributes attributes = FileReader.readAttributes(path + "PlayGolf.txt");
//Carrega os registros da base de dados
List records = FileReader.readDataset(path + "PlayGolf.txt", attributes);
//Instância o primeiro ramo da nossa árvore
Node root = new Node();
root.setData(records);
//Inicia o processamento da árvore
ID3 id3 = new ID3();
id3.generateTree(records, root, attributes);
//Imprime a arvore resultante no arquivo Result.txt
PrintWriter writer = null;
try {
writer = new PrintWriter(path + "Result.txt", "UTF-8");
} catch (FileNotFoundException | UnsupportedEncodingException e) {
e.printStackTrace();
}
FileWriter.writeTree(root, writer, 0);
//Fecha o arquivo
writer.close();
}
}
Destacando os pontos importantes da classe que necessitam alteração para a execução, temos:
Aqui deverá estar a massa de dados que iremos usar e será o caminho em que será salvo o arquivo de retorno:
String path = "C:\\desenvolvimento\\IA\\";
Substituir o nome do arquivo com a massa de dados para o arquivo correto:
//Carrega os atributos da base de dados
ListDiscreteAttributes attributes = FileReader.readAttributes(path + "PlayGolf.txt");
//Carrega os registros da base de dados
List<record> records = FileReader.readDataset(path + "PlayGolf.txt", attributes);
Arquivo com a árvore resultante:
writer = new PrintWriter(path + "Result.txt", "UTF-8");
ID3.java
Classe core do código do algoritmo, nela são realizados toda a lógica de classificação de atributos e de divisão da massa de dados. Aqui também são gerados os ramos da árvore. Todo o processamento é realizado de forma recursiva.
public class ID3 {
/**
* Gera a arvore de decisao de forma recursiva.
*
* @param records - Dados a serem classificados pela arvore
* @param root - No da arvore do topo da arvore para essa iteracao
* @param learningSet - Atributos a serem utilizados pelo classificador
* @return - Arvore de decisao
*/
public Node generateTree(List<Record> records, Node root, ListDiscreteAttributes learningSet) {
//Inicializa as variaveis para selecionar o melhor atributp
int bestAttribute = -1;
double bestGain = 0.0;
//Calcula a entropia para os registros a serem considerados
root.setEntropy(Entropy.calculateEntropy(root.getData(), learningSet));
//Condicao de para da arvore
if(root.getEntropy() == 0) {
return populateResult(root.getData(), root, learningSet);
}
//Avalia cada atributo ainda nao utilizado nesse galho da arvore
for(int i = 0; i < learningSet.getAttributeQuantity() - 1; i++) {
double entropy = 0;
LinkedList<Double> entropies = new LinkedList<Double>();
LinkedList<Integer> setSizes = new LinkedList<Integer>();
//Faz um de para com a posicao do atributo no vetor de atributos com a posicao real dele na base de dados
int attributePositionRecord = Utils.getAttributePositionOnRecords(learningSet.getAttributeInfo(i), root.getData().get(0));
//Itera por cada possivel valor do atributo selecionado
for(int j = 0; j < learningSet.getAttributeInfo(i).getListAttributes().getQuantity(); j++) {
//Pega os registros com o valor a ser considerado
ArrayList<Record> subset = Utils.subset(root, attributePositionRecord, j);
//Pega o tamanho desse subset
setSizes.add(subset.size());
//Calcula a entropia para o subset
if(subset.size() != 0) {
entropy = Entropy.calculateEntropy(subset, learningSet);
entropies.add(entropy);
} else {
entropies.add(0.0);
}
}
//Calcula o ganho de informacao
double gain = InformationGain.calculateGain(root.getEntropy(), entropies, setSizes, root.getData().size());
//Se for melhor do que o melhor atributo atualiza os valores
if(gain > bestGain) {
bestAttribute = i;
bestGain = gain;
}
}
//Caso exista um atributo a ser considerado
if(bestAttribute != -1) {
//Preenche o no da arvore com os valores desse atributo
AttributeInfo chosen = learningSet.getAttributeInfo(bestAttribute);
String testedAttributeName = root.getTestAttribute().getValue();
root.setTestAttribute(chosen);
root.setValue(testedAttributeName);
root.children = new Node[chosen.getListAttributes().getQuantity()];
root.setUsed(true);
learningSet.removeAttribute(bestAttribute);
int bestAttributePositionRecord = Utils.getAttributePositionOnRecords(chosen, records.get(0));
//Preenche as folhas geradas a partir desse atributo
for (int j = 0; j < chosen.getListAttributes().getQuantity(); j++) {
root.children[j] = new Node();
root.children[j].setParent(root);
root.children[j].setData(Utils.subset(root, bestAttributePositionRecord, j));
root.children[j].getTestAttribute().setValue(chosen.getListAttributes().getValue(j));
}
//Itera recursivamente pelos filhos
for (int j = 0; j < chosen.getListAttributes().getQuantity(); j++) {
generateTree(records, root.children[j], learningSet.clone());
}
}
//Metodo de para do algoritmo
else {
return populateResult(root.getData(), root, learningSet);
}
return root;
}
/**
* Popula as folhas durante as condicoes de para do algoritmo
*
* @param records - Registros filhos dessa folha
* @param root - No com o atributo que gerou a folha
* @param learningSet - Atributos ainda nao utilizados no ramo
* @return
*/
private Node populateResult(List<Record> records, Node root, ListDiscreteAttributes learningSet) {
AttributeInfo chosen = learningSet.getAttributeInfo(learningSet.getAttributeQuantity() - 1);
root.children = new Node[1];
root.children[0] = new Node();
root.children[0].setParent(root);
int classAttributePositionRecord = Utils.getAttributePositionOnRecords(chosen, records.get(0));
int resultPosition = Utils.getMajority(root.getData(), learningSet.getAttributeInfo(learningSet.getAttributeQuantity() - 1).getListAttributes(), classAttributePositionRecord);
root.children[0].getTestAttribute().setValue(chosen.getListAttributes().getValue(resultPosition));
return root;
}
}
Entropy.java
Classe que realiza o cálculo da entropia de um determinado conjunto de dados.
public class Entropy {
/**
* Metodo que dado um conjunto de registros e os atributos a serem calculados, calcula a entropia
* do conjunto
*
* @param data - registros do qual sera calculado a entropia
* @param learningSet - atributos
* @return
*/
public static double calculateEntropy(List<Record> data, ListDiscreteAttributes learningSet) {
double entropy = 0;
if(data.size() == 0) {
return 0;
}
//Obtem a posicao em que se encontra a classe no conjunto de atributos
int positionClass = learningSet.getAttributeQuantity() - 1;
//Obtem a posicao em que se encontra a classe nos registros
int positionClassRecord = data.get(0).getAttributes().size() - 1;
//Itera pelas classes existentes
for(int i = 0; i < learningSet.getAttributeInfo(positionClass).getListAttributes().getQuantity(); i++) {
int count = 0;
for(int j = 0; j < data.size(); j++) {
Record record = data.get(j);
if(record.getAttributes().get(positionClassRecord).getValue() == i) {
count++;
}
}
//Calcula a entropia
double probability = count / (double)data.size();
if(count > 0) {
entropy += -probability * (Math.log(probability) / Math.log(2));
}
}
return entropy;
}
}
InformationGain.java
Classe que realiza o cálculo do ganho de informação de um determinado atributo em um determinado conjunto de dados.
public class InformationGain {
/**
* Calcula o ganho de informacao de determinado atributo
*
* @param rootEntropy - Entropia do conjunto como um todo
* @param subEntropies - Entropia dos possiveis subgrupos do atributo
* @param setSizes - Tamanho dos possiveis subgrupos do atributo
* @param data - Quantidade de registros total
* @return
*/
public static double calculateGain(double rootEntropy, LinkedList<Double> subEntropies, LinkedList<Integer> setSizes, int data) {
double gain = rootEntropy;
for(int i = 0; i < subEntropies.size(); i++) {
gain += -((setSizes.get(i) / (double)data) * subEntropies.get(i));
}
return gain;
}
}
Essas são as principais classes que compõe o projeto para geração de árvores de decisão, o projeto se encontra no link:
https://github.com/dsestaro/Algorithms
Todos as implementações feitas aqui no blog irão ser commitadas nesse mesmo repositório.